How to Build Your Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG): A Deep Guide
Retrieval-Augmented Generation (RAG) has emerged as the dominant paradigm for deploying Large Language Models (LLMs) in real-world applications. This post is based on the teaching experience at 1DT104 Project in Computer Systems, Uppsala University, where a group students tried to create a chatbot based on TSpec-LLM dataset to explain the points upon requested.
At its core:
RAG = Retrieval + LLM Generation
Instead of asking the LLM to recall everything from its parameters, RAG retrieves external, domain-specific information and injects it into the prompt for grounded, reliable outputs.
This document provides a deep dive into RAG:
- 1. Why RAG is Needed
- 2. The RAG Workflow
- 3. Data Preparation
- 4. Query → Retrieval → Answer
- 5. Advanced RAG Techniques
- 6. Evaluation & Tuning
- 7. Summary
1. Why RAG is Needed
LLMs are powerful but limited:
- Knowledge cut-off: e.g., GPT-4 only knows up to 2023-10.
- Domain gaps: cannot answer private or specialized topics (e.g., enterprise docs).
- Hallucinations: fluent but fabricated answers. All deep learning models are fundamentally based on mathematical probability. The output of a model is essentially a sequence of numerical computations, and large models are no exception. This is why they often produce confident but incorrect responses, especially in areas where the model lacks knowledge or is not well-suited to the task.
- Data governance: fine-tuning requires exposing sensitive data. Data security is critical for enterprises, and no company, especially large ones, will risk exposing private data to third-party platforms. As a result, solutions that rely solely on general large models must compromise between security and performance.
RAG solves these problems by:
- Keeping data in external retrievers (vector DBs, SQL, graph DBs).
- Feeding only relevant slices into the LLM.
- Allowing continuous updates without re-training the model.
2. The RAG Workflow
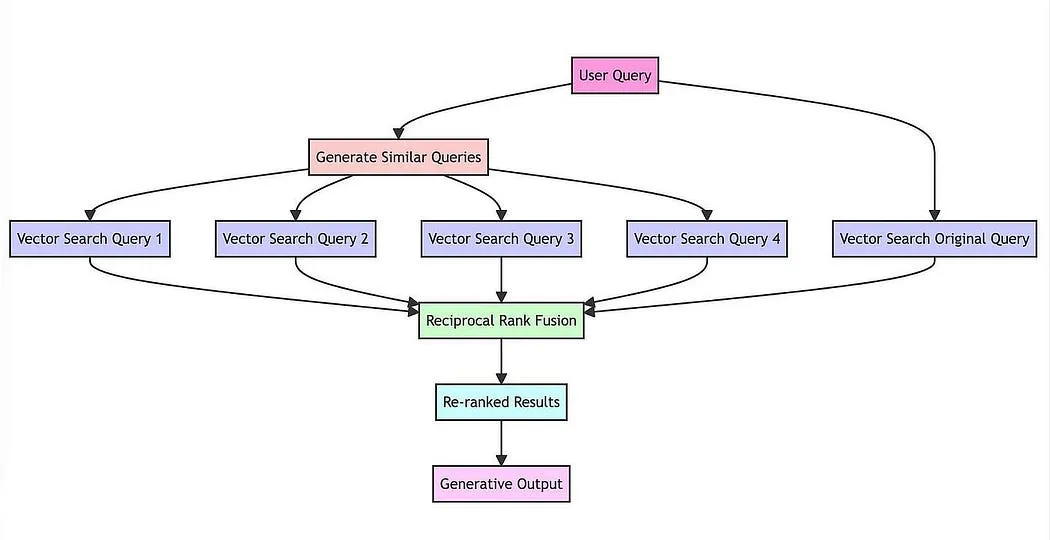
The core idea is to use an LLM to generate multiple queries, with the expectation that these queries will bring out different aspects of the problem in context. You can then perform vector search with the generated queries (as discussed in earlier parts of this series) and re-rank the content based on how it appears in the result set.
 Source: Substack image asset
Source: Substack image asset
RAG has two main phases:
Offline (Indexing / Data Prep)
- Ingest raw documents
- Chunk them into smaller units
- Generate embeddings
- Store embeddings + metadata in a retriever (vector DB, hybrid DB)
Online (Query → Answer)
- User query
- Query embedding + similarity search
- Retrieve top-k relevant chunks
- Inject chunks into LLM prompt
- Generate grounded answer
Workflow Diagram (simplified):
The complete RAG application process mainly consists of two stages:
-
Data Preparation Stage: Data extraction → Text segmentation → Vectorization (embedding) → Data storage
-
Application Stage: User query → Data retrieval (recall) → Prompt injection → LLM answer generation
 Source: Author-generated diagram.
Source: Author-generated diagram.
Simply put, RAG works by retrieving relevant knowledge and incorporating it into the prompt, enabling the large model to generate more accurate answers. Its core can be understood as “retrieval + generation”: the retrieval stage leverages the efficient storage and search capabilities of vector databases to recall target knowledge, while the generation stage uses large models and prompt engineering to make effective use of the recalled knowledge and produce the final answer.
3. Data Preparation
Data Extraction and Chunking
Data comes in PDFs, Word, HTML, or SQL sources. They must be normalized into plain text with metadata (author, date, section).
Chunking balances context size and retrieval precision:
- Fixed size (e.g., 512 tokens with overlap) – simple and robust.
- Sentence/paragraph based – preserves semantics.
- Hybrid hierarchical – sections → paragraphs → sentences.
Formally, if a document $D$ is tokenized into ${t_1,…,t_n}$, chunking is a partition:
\[D = \bigcup_{i=1}^m C_i, \quad |C_i| \leq L\]where $L$ is maximum tokens per chunk.
Embeddings and Storage
Embeddings map text into vectors: $f: \mathbb{R}^T \to \mathbb{R}^d$.
Examples: ChatGPT-Embedding, BGE, gemini-embedding-001.
Similarity is via cosine similarity:
\[\text{sim}(q, c) = \frac{f(q) \cdot f(c)}{\|f(q)\| \|f(c)\|}\]Stored in FAISS, Pinecone, Milvus, pgvector, etc.
Vectorization converts text data into vector matrices, a step that directly impacts retrieval performance. Common embedding models, as shown in the table, meet most needs. In specialized cases, such as handling rare proprietary terms or optimizing accuracy, organizations can fine-tune open-source models or train custom embeddings. Once data is vectorized, it is indexed and stored in a database. For RAG scenarios, typical options include FAISS, ChromaDB, Elasticsearch, and Milvus. The choice of database should be based on business context, hardware, and performance requirements.
4. Query → Retrieval → Answer
In the application stage, user queries trigger efficient retrieval methods that recall the most relevant knowledge and integrate it into the prompt. The large model then uses both the query and the retrieved knowledge to generate an answer. Key steps include data retrieval and prompt construction. Common retrieval methods are similarity search and full-text search, which can be combined to improve recall.
Similarity search calculates scores between the query vector and stored vectors, returning the highest-scoring records. Typical measures include cosine similarity, Euclidean distance, and Manhattan distance. Full-text search builds an inverted index during data storage and retrieves records through keyword matching.
At inference:
- Encode query: $q \mapsto f(q)$
- Retrieve top-k documents $C_1,…,C_k$
- Build augmented prompt
- LLM generates grounded response.
The prompt, as the direct input to the model, is a critical factor for output accuracy. In RAG, the prompt usually includes task description, retrieved background knowledge, and user instructions. Depending on the task and model performance, additional instructions can be added to optimize results. Prompt design follows no fixed syntax and relies heavily on personal experience. In practice, it often requires targeted adjustments based on the actual outputs of the large model.
Prompt Example:
[Task Description]
Assume you are a professional customer service assistant. Please answer with reference to the background knowledge.
[Background Knowledge]
{content} // Relevant text retrieved from the database
[Question]
What is the battery life of the Stone Robot Vacuum P10?
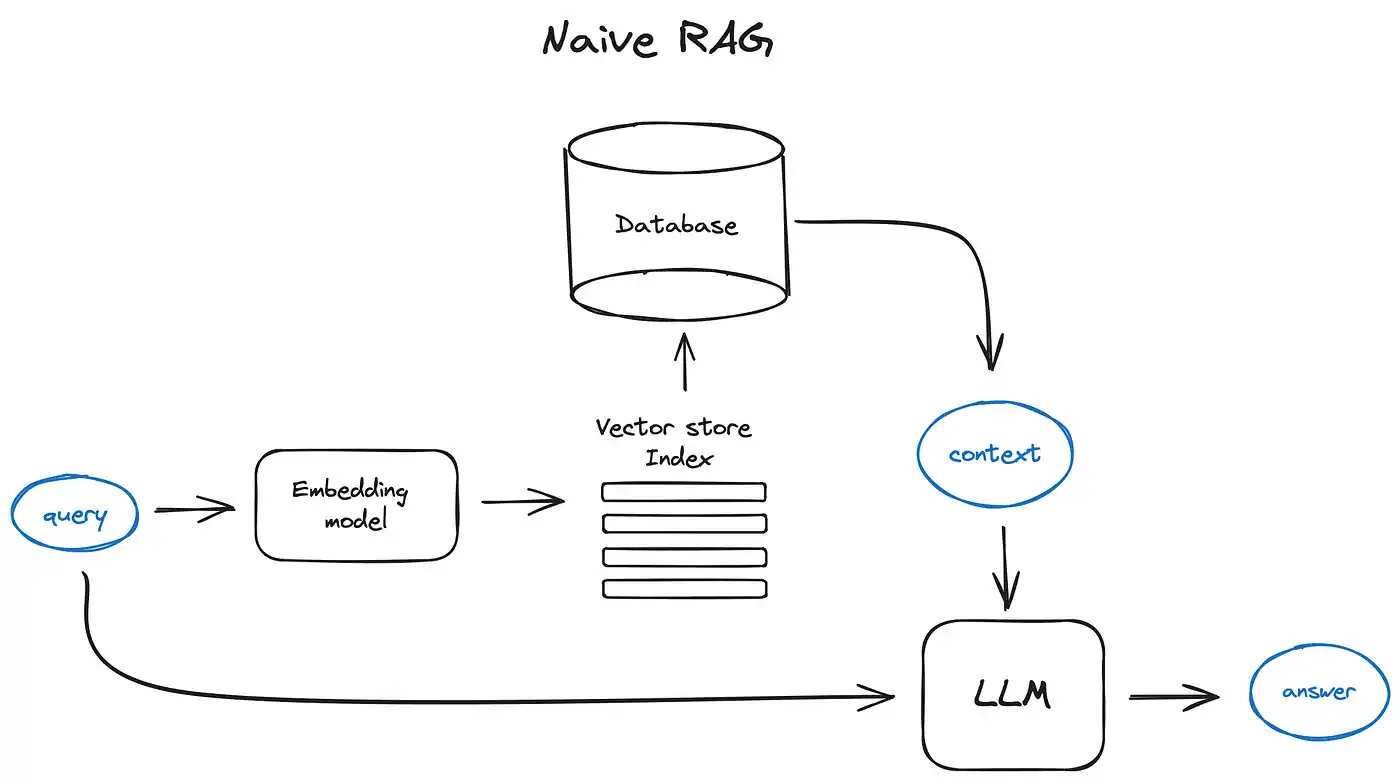
A standard RAG workflow begins by splitting text into chunks and embedding them into vectors using a Transformer encoder model. These vectors are stored in an index, and a prompt is created to instruct the LLM to answer user queries based on the retrieved context.
At runtime, the user query is vectorized with the same encoder model. The query vector is then searched against the index to find the top-k results. The corresponding text chunks are retrieved from the database and included as context in the LLM prompt.
An example prompt looks like this:
def question_answering(context: str, query: str):
prompt = f"""
Answer the user query below using the context provided.
Query: ```{query}```
Context: ```{context}```
- If relevant information is found in the context, use it to answer.
- If the context does not contain relevant information, answer on your own but tell the user that no supporting context was available.
- Keep the answer concise and under 80 tokens.
"""
response = get_completion(prompt, model="gpt-5")
answer = response.choices[0].message["content"].strip()
return answer
Prompt engineering is a simple yet effective way to improve the performance of the RAG pipeline. For practical guidance, you can refer to OpenAI’s detailed prompt engineering guide.
 Source: Zhihu image asset
Source: Zhihu image asset
5. Advanced RAG Techniques
 Source: Zhihu image asset
Source: Zhihu image asset
5.1 Chunking
As talked earlier, Transformer models have fixed input sequence lengths. Even if the context window is large, the vector of a single sentence or a few sentences often represents semantic meaning better than the vector of several pages. Therefore, data is divided into chunks, splitting the original document into blocks of manageable size without losing meaning. Many text splitter implementations can accomplish this task.
The size of each chunk is an important consideration. It depends on the embedding model and the token capacity it can handle. For example, sentence transformers based on BERT support up to 512 tokens, while OpenAI’s ada-002 can process longer sequences up to 8191 tokens. The tradeoff is that a large context helps reasoning in the LLM, while smaller, more specific embeddings enable more effective search. Research exists on optimal chunk size selection. In LlamaIndex, the NodeParser class provides strong support for this task, with advanced options such as custom text splitters, metadata, and parent–child block relations.
5.2 Vectorization
The next step is vectorisation, choosing a search-optimized model to embed the chunks. Options include models such as bge-large or the E5 embedding family. The MTEB leaderboard provides updated performance comparisons. For an end-to-end implementation of chunking and vectorisation, LlamaIndex includes complete examples of ingestion pipelines.
5.3 Retrival
The core of the RAG pipeline is the Retrival, which stores the embedded vectors from the previous step. The most basic form is a flat index that computes distances between the query vector and all stored vectors. For efficient retrieval at the scale of ten thousand or more elements, vector indices such as FAISS, nmslib, and Annoy should be used. These rely on approximate nearest neighbor algorithms such as clustering, tree structures, or HNSW. Managed solutions also exist, such as OpenSearch, ElasticSearch, and vector databases including Pinecone, Weaviate, and Chroma, which automate ingestion and retrieval. Depending on indexing choice, data type, and search requirements, metadata can also be stored and used for filtering, for example by date or source. LlamaIndex supports a range of vector indices and remains compatible with simpler forms such as list indices, tree indices, and keyword tables.
Hierarchical indexing is useful for large databases. One index holds summaries while another stores document chunks. Queries first pass through the summary index to filter relevant documents before searching within the associated chunks.
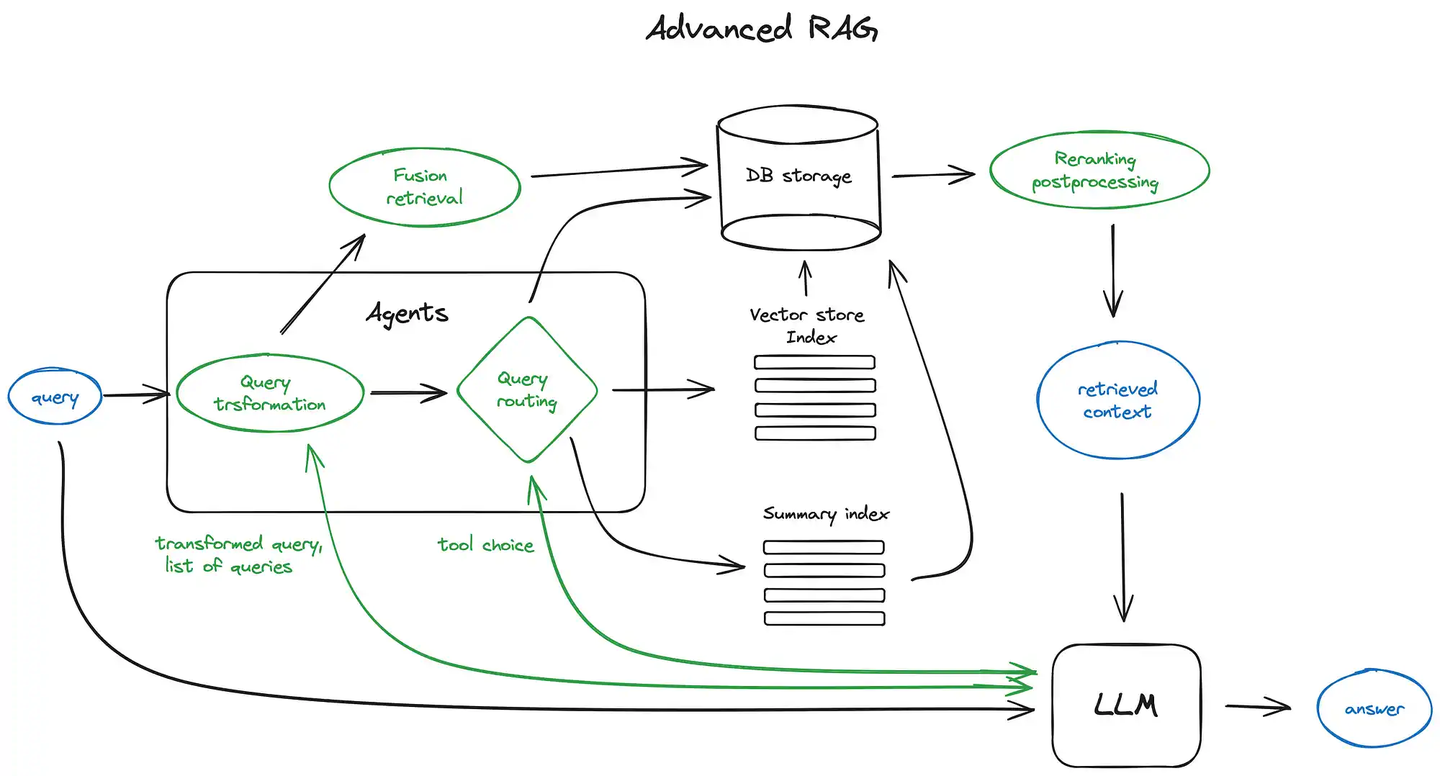
Alternative retrieval strategies improve quality. One method generates hypothetical questions for each chunk, embeds them, and searches against these instead of the original chunks. This often yields better semantic similarity. Another approach, HyDE, generates a hypothetical response to the user query, embeds it, and uses it to enhance search. Content expansion strategies also extend context windows. Sentence window retrieval embeds each sentence separately, finds the most relevant one, then expands context to include surrounding sentences. Parent document retrieval embeds child chunks but merges them into larger parent blocks when multiple children from the same parent are retrieved, ensuring broader context is provided to the LLM.
Hybrid or fusion retrieval combines sparse keyword search, such as BM25, with dense semantic search. Their results are merged using techniques such as Reciprocal Rank Fusion. Both LangChain and LlamaIndex support ensemble retrievers that mix different retrieval strategies.
After retrieval, post-processing improves results through filtering and reranking. This can be done by similarity scores, metadata constraints, or cross-encoder models. APIs from providers like Cohere and sentence-transformer rerankers are commonly used. This stage produces the final set of context passages passed to the LLM.
5.4 Quary
More advanced techniques include query transformation and routing. Query transformation uses the LLM as a reasoning engine to modify user queries to improve retrieval. For complex queries, the model can decompose them into multiple sub-queries. For example, if asked which of LangChain or LlamaIndex is more popular on GitHub, the query is decomposed into “How many stars does LangChain have on GitHub?” and “How many stars does LlamaIndex have on GitHub?”. These are executed in parallel, and the results are aggregated into a single prompt. LangChain implements this as a multi-query retriever and LlamaIndex provides a sub-question query engine. Step-back prompting generates a more general query to fetch higher-level context alongside the original search. Query rewriting rephrases the input to improve matching, and both LangChain and LlamaIndex support it.
Query routing is another LLM-driven decision step. The model determines the next action given a user query, such as summarizing, searching a particular index, or combining results from multiple routes. Routing is also used to select among data stores, which may include vector databases, graph databases, relational stores, or hierarchical indices. Multi-document settings often combine summary indices with chunk indices. A router is defined by specifying its set of possible actions. Routing decisions are produced by the LLM in a structured format, directing the query to the chosen index. In some cases, queries can also be sent to subchains or other agents. Both LangChain and LlamaIndex support query routing.
5.5 Chat Engine
To support multi-turn conversations, RAG systems can include a chat engine that preserves conversational context. This is needed for follow-up questions, pronoun resolution, and references to prior exchanges. One approach is context compression, combining chat history with the user query before retrieval. A simple form is the ContextChatEngine, which retrieves relevant context and merges it with the memory buffer before passing to the LLM. A more advanced form is CondensePlusContext, where chat history and the last user message are compressed into a refined query, which is then used for retrieval. LlamaIndex also supports OpenAI-agent-based chat engines for more flexible modes, and LangChain integrates OpenAI’s function calling API. Other forms, such as ReAct agents, also exist.
5.6 Agents
 Source: Zhihu image asset
Source: Zhihu image asset
Agents are another layer of capability. They emerged soon after the first LLM APIs were introduced. The idea is to provide an LLM with reasoning capacity, a set of tools, and a defined task. Tools may include deterministic functions such as API calls, code functions, or even other agents. This chaining idea gave LangChain its name.
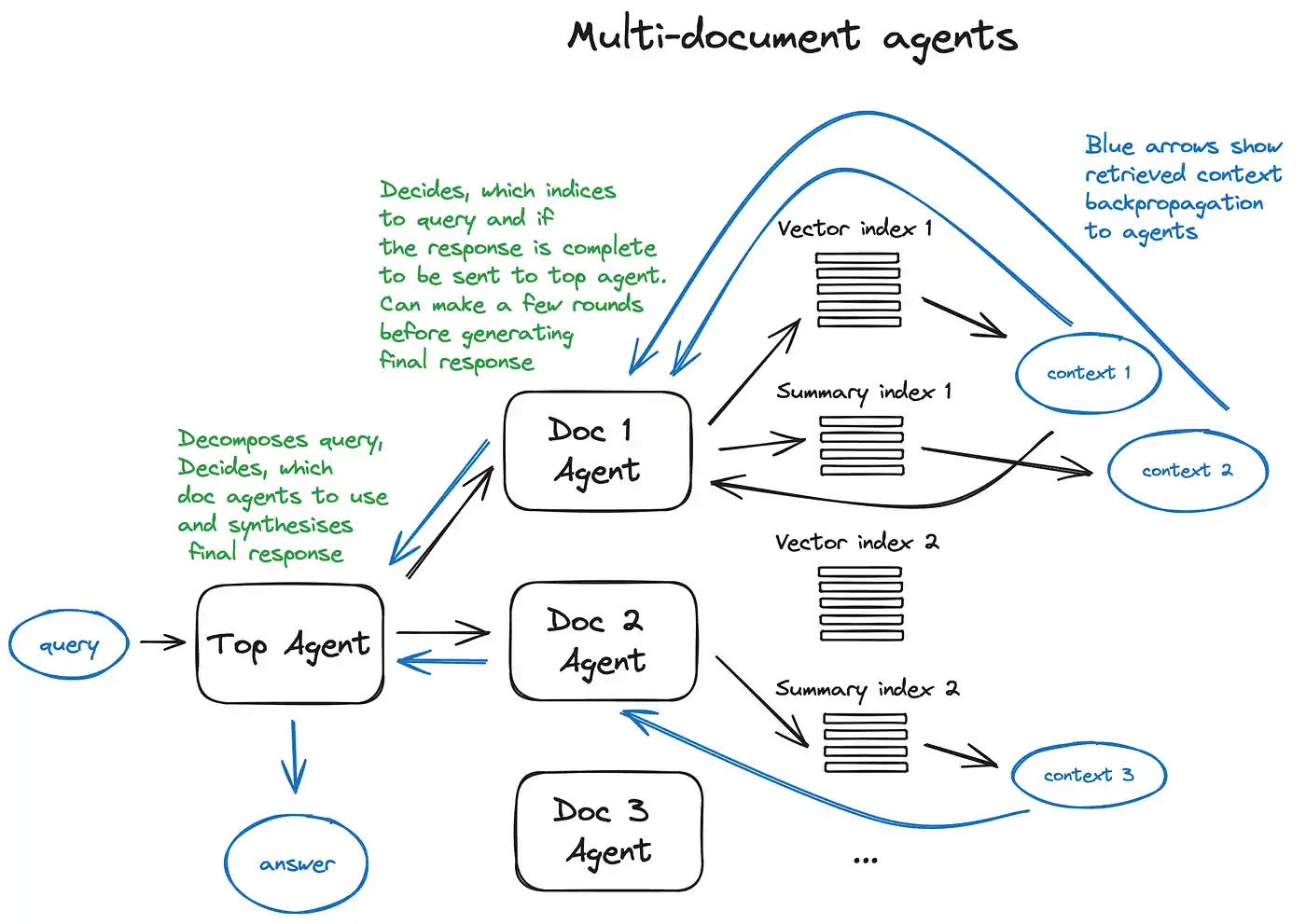
Agents themselves are a deep subject. One practical case is multi-document retrieval, where each document has its own agent capable of summarization and QA, and a top-level agent manages query routing and answer aggregation. Each document agent may use both vector and summary indices. For the top-level agent, all document agents are tools. This illustrates an advanced RAG architecture in which agents perform many routing decisions, enabling cross-comparisons and synthesis across multiple documents.
OpenAI Assistants are a related concept, recently introduced. They integrate knowledge storage, chat history, and document upload, with function calling to translate natural language into structured API calls. In LlamaIndex, the OpenAIAgent class combines this with ChatEngine and QueryEngine, supporting context-aware conversations and multi-function execution.
The limitation of multi-agent setups is speed. Because each agent requires multiple back-and-forth LLM calls, the process is slower. LLM calls are usually the most time-consuming part of a RAG pipeline, whereas search itself is optimized for speed. For large multi-document storage, simplifying the configuration may be necessary to scale effectively.
5.7 Reponse Synthesis
The final step of a RAG pipeline is response synthesis. The simplest method is to concatenate all retrieved context above a relevance threshold with the user query and pass it to the LLM. More advanced approaches involve multiple LLM calls. These include sending context in separate chunks and aggregating the responses, summarizing retrieved context to fit within prompt limits, or generating multiple answers from different contexts and merging them. The goal is to balance completeness of evidence with quality of the generated answer.
- Multi-Query Fusion: Generate multiple reformulations and fuse results using Reciprocal Rank Fusion (RRF):
- HyDE (Hypothetical Document Embeddings): LLM creates pseudo-answer, embed that instead of query.
- Content Expansion: expand around sentence or parent document.
- Reranking: cross-encoders refine retrieved docs.
- Query Transformation: rewriting, decomposition, step-back prompting.
- Query Routing: classify query to domain-specific retriever.
- Agents + RAG: retrieval becomes one tool in multi-step reasoning.
6. Evaluation & Tuning
- Retrieval Metrics: Precision@k, Recall@k, nDCG.
- Generation Metrics: Faithfulness, Factuality, Conciseness.
- Tooling:
- Ragas (auto eval)
- TruLens (faithfulness)
- LangSmith (tracing)
- LlamaIndex evaluators
6.1 Fine Tuning
This approach focuses on fine-tuning both the Transformer encoder and the LLM. The encoder affects embedding quality, which in turn determines the quality of context retrieval. The LLM is responsible for making the best possible use of the provided context to answer user queries.
One significant advantage today is the ability to use advanced LLMs such as GPT-4 to generate high-quality datasets. However, it is important to note that fine-tuning a base model on a small synthetic dataset may reduce its generalization ability. In one experiment, the authors fine-tuned the bge-large-en-v1.5 encoder and found that the improvement in retrieval quality was limited. This is because the latest Transformer encoders optimized for search are already highly effective.
If the base encoder cannot be fully trusted, a cross-encoder can be used to rerank retrieved results. The process works as follows: the query and each of the top-k retrieved text chunks are concatenated with a [SEP] token separator and sent to the cross-encoder. The model is then fine-tuned to output 1 for relevant chunks and 0 for irrelevant ones.
Recently, OpenAI introduced APIs for LLM fine-tuning. LlamaIndex provides a tutorial on fine-tuning GPT-3.5-turbo in a RAG setup. Using the ragas evaluation framework, fidelity improved by 5%, showing that the fine-tuned GPT-3.5-turbo made better use of retrieved context compared to the base model.
Meta AI Research recently proposed RA-DIT: Retrieval-Augmented Dual Instruction Tuning, a more advanced method that jointly fine-tunes the LLM and retriever (the dual encoder in the original paper) using triplets of query, context, and answer. This approach has been applied with the OpenAI fine-tuning API as well as with the open-source Llama-2 model. Compared with Llama-2 65B equipped with RAG, RA-DIT fine-tuning improved performance by around 5% on knowledge-intensive tasks and by several percentage points on commonsense reasoning tasks.
7. Summary
- RAG grounds LLMs in external, dynamic knowledge.
- Strong performance depends on chunking, embeddings, retrievers.
- Advanced methods (fusion, reranking, routing) mitigate limitations.
- Evaluation must test both retrieval relevance and answer grounding.
RAG is more than a patch; it is a modular AI architecture for robust, domain-specialized systems.